
Archiving with Are.na
Connected knowledge collection with community: inspirations and practices for archival

Introduction: What’s Are.na? As tools, community and culture
I often describe Are.na as “Pinterest for nerds”, a cheeky description that misses some of its character. Are.na is a powerful tool for hobbyists, students or researchers to collect knowledge on the internet — featuring web and mobile tools for saving and organizing information into “channels”.
As a tool or product, its features and minimal design lend well to use-cases like mood boarding, reading lists, quote collections, or journals. The fundamental building “blocks” and “channels” are versatile in supporting public and private collaboration (notably DMs as shared private channels), knowledge sharing and appropriate attribution through metadata features.
As a community and culture, I’ve found the variety of uses by members compelling and the diverse interactions welcoming. I’ll only scratch the surface here, as the direct experience speaks for itself, and a glimpse is in connections made by folks like: Alice Otieno, Rodrigo Tello, Branden Collins, Omayeli Arenyeka, Wale Boyo and many others.
Why Archive on Are.na?
To speak a bit personally about my archival practice and use of Are.na: In 2019, I started using Are.na to catalog references about African philosophy, after being spurred on by an old manager and fellow philosophy nerd by the question: “who are some African philosophers I should refer to”? Later, with a breakup I started journaling to self-reflect, putting some of those philosophies collected on Are.na into practice. From 2020 till now, especially in light of global events, my archival practice has moved into the areas of history, sustainability, psychology and socio-technical development. Most recently, in further reflection on my growth and multi-disciplinary perspective, I’ve found compelling references in psychology that integrate spirituality and mythology with modern neuro and social science. This combination of intentional research and personal reflection is what characterizes my archival practice today.
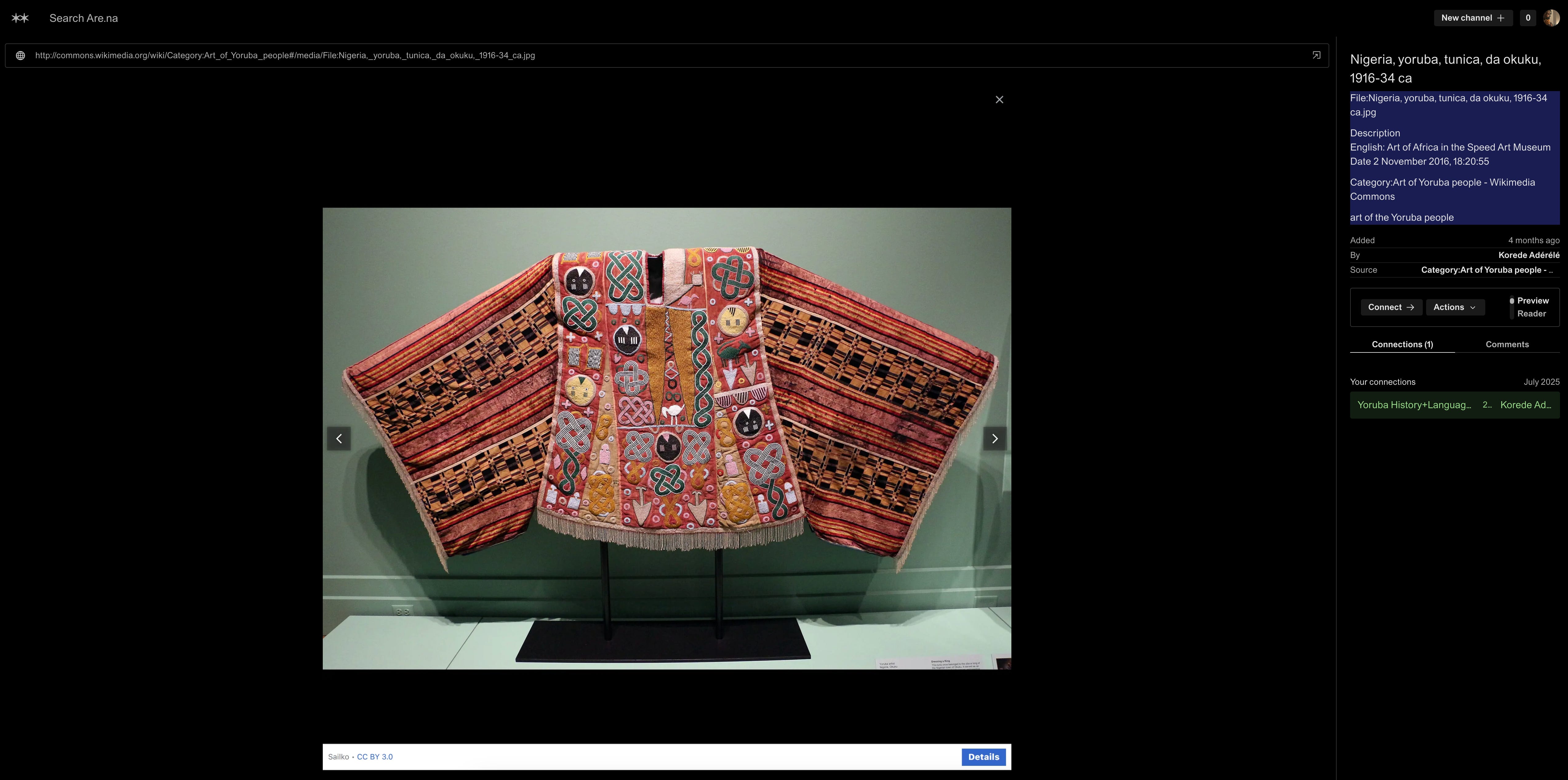
My threads of research in social science and technology are steeped in history and geopolitics as the reference frame. On Are.na, this looks like channels on history and anthropology, with a focus on African states and cultures familiar to me like the Yoruba, channels on permaculture as sustainable ancestral technology, and also channels on topics in psychology, physical science, technology and computing. The contents of these channels are biographies, key events and concepts, articles or papers in various domains. These vary in media type from images, pdfs, web pages, including lots of Wikipedia and YouTube videos, especially for Permaculture content and select documentaries. I strive to ensure the blocks are attributed and include metadata.
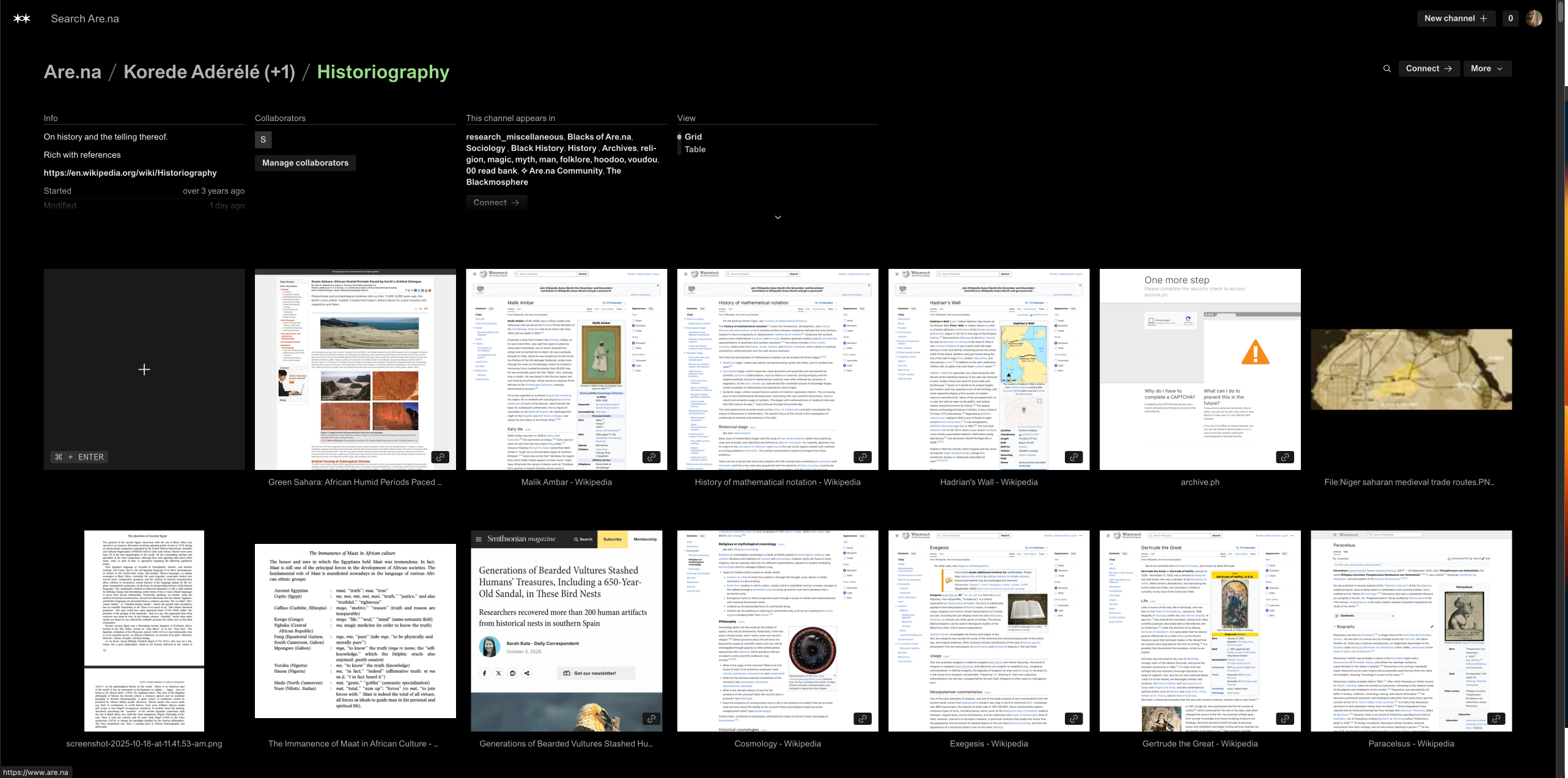
Are.na’s toolset, and open culture have made it a great place to explore these interests. My practice has grown in size, scope and sophistication over the years, partly inspired by the rigor and consistency by which other community members practice. My timeline and interactions on Are.na strongly reflect the development of my multi-disciplinary interests, and also my synthesis of this perspective.
How I use Are.na for Archival Practice
I generally add stuff to Are.na passively, when I come across topics of interest while scrolling social media, or actively, when I’m focused on uncovering references for a particular topic. In either case, I can use Are.na’s ecosystem of browser extensions, and share widgets to save a new reference from wherever. I often start with Wikipedia and mine it for secondary sources, picking up webpages, papers and images that illustrate a topic. Are.na does well to scrape webpage data, including metadata and the full text content for the in-app “reader” view.
Are.na’s also handles raw files like images and PDFs in an important way, in that it saves a copy on its own cloud, so there’s no concern about link rot to the original files. That being said, images, PDFs and other raw files are not automatically parsed for content or metadata, so in this case I strive to add the metadata manually, including more readable names, descriptions and a link to where the image/PDF was retrieved from. One way to make this easier is to simply copy text from the source page or from the image itself where applicable, given most modern photo editors have basic OCR. For example, I frequently save Wikipedia images and copy their relevant Wikimedia metadata details. Also, I take photos of key pages in physical books in my research area, use my phone’s OCR feature to copy the text, and post the image to Are.na along with relevant metadata (like title, chapter and page number) and the OCR text (after some mild manual transcribing).

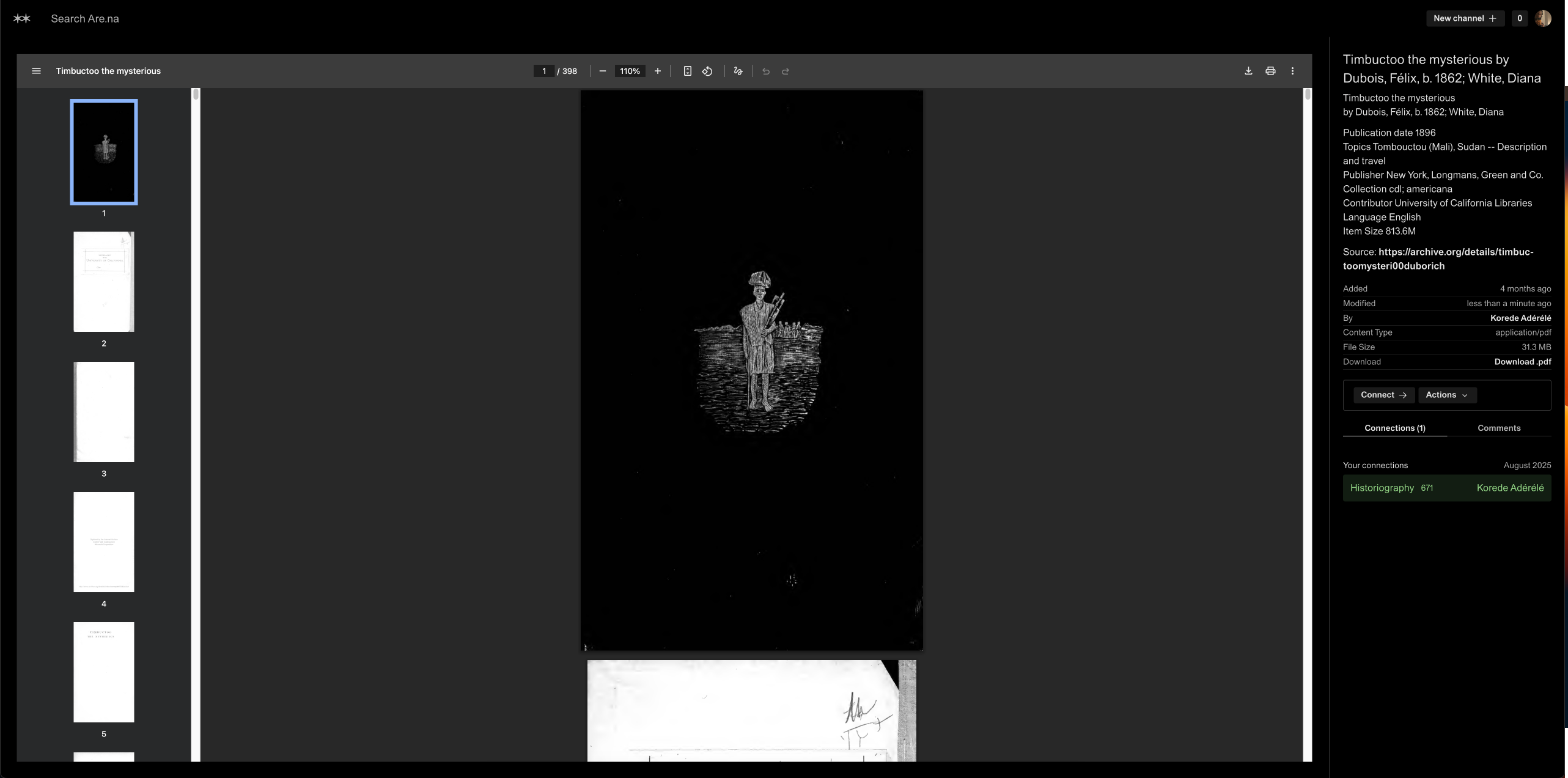
Another site I often glean archival information from is Internet Archive (archive.org), where many old books and images are available. In this case, I will either save the webpage with a reader view to some book, or in the case where a full text PDF is available add it to Are.na, including context and a link to the reader page for more detailed context. Relatedly, the IA’s Wayback Machine is a critical tool for getting around link rot, and has come in handy many times in letting me uncover old references. In the absence of PDFs of books, I often see images of book covers serve as appropriate references to source material.
Adding context or metadata is key to diligent archival, allowing other folks to get the more value out of my curation of this reference – a culture of such archival attribution enables strong chains of context amidst shares and reshares of information. Such a culture is codified on Are.na with the concept of block connections and source URL-indexing.
Conclusion
To summarize this what, why and how guide behind archiving with Are.na:
Are.na is at its plainest a tool for collecting and categorizing different types of content; in my archival practice I focus on text and images with historical backing, papers, articles, web pages and images
Are.na has some great features for archival: Websites are auto scraped for title, descriptions, metadata and full text. Raw files like PDFs and images are copied to Are.na’s dedicated cloud, but adding additional context to them is very valuable. Full PDF sources are great when they can be found, but book covers can suffice
Are.na enables passive and active archival via a solid ecosystem of browser extensions and share widgets for grabbing content from anywhere
Strong metadata and attribution practices helps with revisiting relevant references in, allowing others to explore more, and generally add depth as well as breath to an archival channel.
Adjacently, in summary of my more personal experience on Are.na:
My archival practice has grown from something deeply personal, to something I hope to serve others and the broader community with. This post is an attempt at such service.
The archives I build on Are.na reflect multi-disciplinary interests that are increasingly integrated into a personal thesis that’s in service of trans-personal goals.
The Are.na toolset and community has been indispensable for me, and I’d like to give back in this form of reflection and further discussion on archival practice.
Thanks for reading :)
This is the 3rd or 4th piece on Substack that I’ve read that has mentioned Are.na. As someone who loves to explore/learn about many different things, I think I’m gonna check out this platform and start building my digital garden. Thanks for this.
Are.na has been my favorite corner of the internet for learning and curation for a while now. Loved reading your thoughts on it and hope it stays a safe place for intelligence and ideas!